
hajimi 的前缀表示重要程度,字符越多越重要。
技巧
hajim 快读(不会写不太敢用)
char buf[1 << 21] , *p1 , *p2;#define GC p1 == p2 && (p2 = (p1 = buf) + fread(buf , 1 , 1 << 21 , stdin) , p1 == p2) ? EOF : *p1++inline int read() { int x = 0; bool f = 0; char ch = GC; while(ch > '9' || ch < '0') { if(ch == '-') f = 1; ch = GC;} while(ch >= '0' && ch <= '9'){ x = (x << 1) + (x << 3) + (ch ^ 48); ch = GC; } return f? -x : x;}char buf[1 << 21] , *p1 , *p2;#define GC p1 == p2 && (p2 = (p1 = buf) + fread(buf , 1 , 1 << 21 , stdin) , p1 == p2) ? EOF : *p1++inline int read() { int x = 0; char ch = GC; while(ch > '9' || ch < '0') ch = GC; while(ch >= '0' && ch <= '9'){ x = (x << 1) + (x << 3) + (ch ^ 48); ch = GC; } return x;}ha 随机
#include <random>#include <algorithm>
mt19937 rng(114514);printf("%u\n" , rng()); //return unsigned intshuffle(a + 1 , a + 1 + n , rng);
do{ //doit}while(next_permutation(a + 1 , a + 1 + n)); //向后全排列。haj ODT
struct QWQ { int l , r;// mutable QWQ(int _ , int __): l(_) , r(__) {} inline bool operator < (const QWQ &b){ return l < b.l; }}; set <QWQ> s;
inline set <QWQ>::iterator find(int x){ return --s.upper_bound(QWQ(x)); }
inline set <QWQ>::iterator split(int x){ set <QWQ>::iterator it = find(x); if(it -> l == x) return it; int l = it -> l , r = it -> r; s.erase(it); s.insert(QWQ(l , x - 1)); return s.insert(QWQ(x , r)).first;}ha状压枚举子集
for(int T = (S - 1) & S;T;T = (T - 1) & S){ //真子集要从S开始。}数据结构
haj 可并堆
启发式合并
比较简单,小的合并到大的里,暴力合并即可。
但应该不支持修改。
pb_ds
#include<bits/extc++.h>using namespace __gnu_pbds;
__gnu_pbds::priority_queue <int , greater <int> >q; //小根堆
q.push(x); //将数字 x 放入堆中,返回 x 所在迭代器 it。__gnu_pbds::priority_queue<int,greater<int>>::point_iterator it = q.push(x); //默认情况下似乎难以失效q.top(); //返回堆顶的元素。q.erase(it); //将迭代器 it 从堆中消除。q1.join(q2); //将 pq2 放入 pq1 中,同时清空 pq2。q.modify(it , x); //将堆中迭代器为 it 的值改为 x。multiset
字符串类
ha AC自动机
用于求:
个模式串,一个文本串。
可在线性时间内求出每个模式串在文本串中的出现次数。
方法是把模式串插入字典树,构建 fail 数组。
fail[x] 代表字典树上的 x 节点与其有最长相同后缀的节点位置。
怎么求,现在枚举到,子节点为:
- 若
s[fail[x]][i]有值,直接让的 fail 指向其即可。 - 若无,可以尝试
s[fail[fail[x]]][i],一直到有值,或到根节点。
我们采用 bfs 由浅入深遍历,第一种情况照常,第二种情况若某节点缺了某个子节点,可以先将其子节点指向s[fail[x]][i],这样,下一次一情况取到它时,就自动指向了s[fail[fail[x]]][i],类似路径压缩。
我们是如何查询的?首先有一个文本串,和个模式串,我们将插入字典树,查询时遍历,暴力跳,由于跳的 fail 只要非空,它就一定有在中出现,若该节点巧合是模式串结束的点,那么增加答案。
注意到每次跳是 nw->fail[nw]->fail[fail[nw]]…(一条到根的链加一),我们连边由 fail[x] 到 x,这样只需统计子树和即可。
注意重复的情况,可以对每个点再取一次ed[nw]。
inline int qwq(char c){ return c - 'a'//; }
int id[100005] , nwid;int ans[100005];
struct Trie { int son[3000005][6] , cnt; int sum[3000005] , ans[3000005];
inline void insert(int i , string x){ int nw = 0; for_each(x.begin() , x.end() , [&](char c) -> void{ const int u = qwq(c); if(!son[nw][u]) son[nw][u] = ++cnt; nw = son[nw][u]; }); if(!sum[x]) sum[x] = id[i] = ++cnt; else id[i] = sum[x]; }};
struct ACM{ vector <int> g[200005]; Trie trie; int fail[3000005];
inline void build(){ queue <int> q; for(int i = 0;i < 6;i++) if(trie.son[0][i]) q.push(trie.son[0][i]); while(!q.empty()){ int t = q.front(); q.pop(); for(int i = 0;i < 6;i++){ if(trie.son[t][i]){ fail[trie.son[t][i]] = trie.son[fail[t]][i]; g[trie.son[fail[t]][i]].push_back(trie.son[t][i]); q.push(trie.son[t][i]); } else trie.son[t][i] = trie.son[fail[t]][i]; } } }
inline void run(string x){ int nw = 0; for_each(x.begin() , x.end() , [&](char c) -> void{ nw = trie.son[nw][qwq(c)]; //不存在将跳到 fail 处。 trie[nw].ans++; }); auto dfs = [&](int x){ for(int nxt : g[x]){ dfs(nxt); trie[x].ans += trie[nxt].ans; } ans[trie[x].sum] = trie[x].ans; } dfs(0); }}zbj;haji kmp
超级难。
它有一个数组,表示前个字符所构成的串的最长相同真前后缀。
转移比较像 AC 自动机。(字符串下标从 1 开始)
- 若,那么。
- 否则尝试,找到一个可行的,转移。
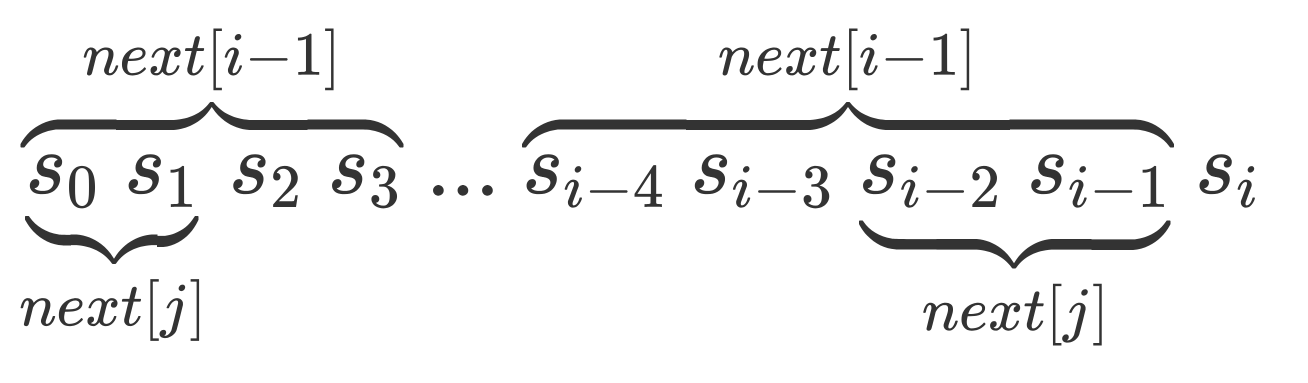
inline void kmp(){ for(int i = 2;i <= m;i++){ int j = nxt[i - 1] + 1; while(j > 1 && p[j] f!= p[i]) j = nxt[j - 1] + 1; if(p[j] == p[i]) j++; nxt[i] = j - 1; } for(int i = 1 , j = 1;i <= n;i++){ while(j > 1 && s[i] != p[j]) j = nxt[j - 1] + 1; if(s[i] == p[j]) j++; if(j == m + 1) printf("%d\n" , i - m + 1); }}对于,设为其可行的相同前后缀长度,于是为的周期,为最小正周期。
hajim hash
const int MOD = 1000000009;int pw[(1 << 20) + 5] , hajimi[(1 << 20) + 5];
inline int gethash(int l , int r){ return (hajimi[r] - 1LL * hajimi[l - 1] * pw[r - l + 1] % MOD + MOD) % MOD;}pw[0] = 1;for(int i = 1;i <= (1 << 20);i++) pw[i] = pw[i - 1] * 379LL % MOD;
for(int i = 1;i <= n;i++) hajimi[i] = (hajimi[i - 1] * 379LL % MOD + s[i]) % MOD;ha Z 函数 / exkmp
为当前最大的使得和完全相等。
维护表和的最长公共前缀。
首先。
然后当前枚举到,当前的已知。分几种情况。
- 那么在有对应。
- 显然。
- 如图。
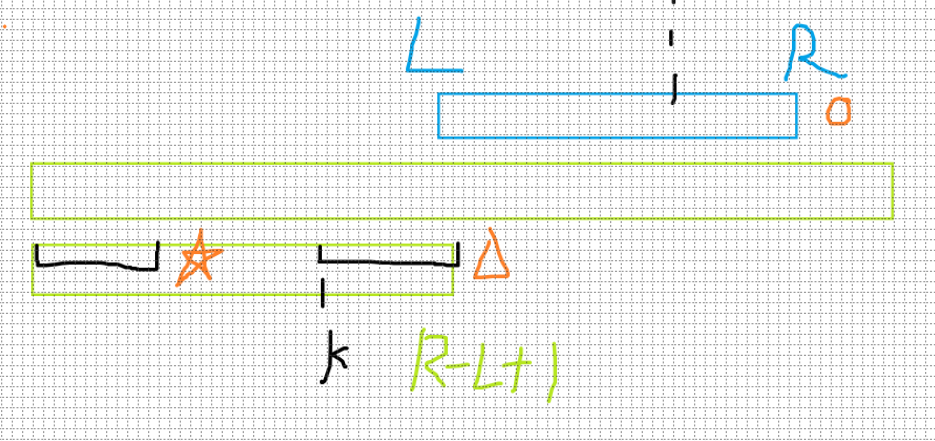
因为,所以三角形=星星
由于 R 是极长的,所以三角形不等于圆
于是圆不等于星星,于是。
- $ z_k=R-L+1 $ 因此上面的第一个条件便就不满足了,因此要暴力往后扩展。inline void zzz(char s[40000005] , int n){ z[1] = n; for(int i = 2 , l = 1 , r = 1;i <= n;i++){ if(i <= r) z[i] = min(z[i - l + 1] , r - i + 1); while(i + z[i] <= n && s[z[i] + 1] == s[i + z[i]]) z[i]++; //暴力扩展 if(i + z[i] - 1 > r) l = i , r = i + z[i] - 1; //维护极大 R }}- P7114:对于,其从 1 开始连续循环出现的次数为。
图
ha 差分约束
给出一组包含个不等式,有个未知数的形如:
的不等式组,求任意一组满足这个不等式组的解。
若是,可以转换成。
最坏。
- 连边后求最短路
将,即从到连一条边权为的边。加入超级源点后求最短路,得到所有最大解。 - 连边后求最长路
将,即从到连一条边权为的边。加入超级源点后求最短路,得到所有最小解。
若最短路存在负环,最长路存在正环则无解。
bool vis[5005]; int cnt[5005] , dis[5005];inline void spfa(){ queue <int> q; q.push(0); memset(dis , 0x3f , sizeof(dis)); dis[0] = 0; while(!q.empty()){ int t = q.front(); q.pop(); if(++cnt[t] > n){ puts("NO"); exit(0); } vis[t] = 0; for(pair <int , int> nxt : g[t]) if(dis[nxt.first] > dis[t] + nxt.second){ dis[nxt.first] = dis[t] + nxt.second; if(!vis[nxt.first]){ vis[nxt.first] = 1; q.push(nxt.first); } } }}
u = read(); v = read(); w = read(); //u<=w+vg[v].push_back({u , w}); //v<=u+wha 同余最短路
完全背包。
假如有,要问小于的数,有多少是能被拼出的。
设表示最小的,其模余。
显然可以写出:
我们看成最短路,即到连长度为的边。总共个点,尽可能小。
答案就是。
haj 二分图/网络流
ha最大匹配
选最多条边,使得没有顶点重复。
这玩意可以用网络流求,求法很板。
ha最小点覆盖
选最少的点,使得每条边都至少有一个顶点被选。
结论:最小点覆盖=最大匹配。
ha最大独立集
选最多点,使得两两间没有边连接。
结论:最大独立集=n-最小点覆盖=n-最大匹配。
技巧
黑白染色->二分图。
求
#include <cstdio>#include <algorithm>#include <cstring>#include <vector>#include <queue>using namespace std;
namespace FSZ { int S , T; vector <pair <int , int> > g[2][1005]; vector <int> id[2][1005];
int dep[1005] , cur[2][1005]; inline bool bfs(){ queue <int> q; q.push(S); memset(dep , 0 , sizeof(dep)); memset(cur , 0 , sizeof(cur)); dep[S] = 114; while(!q.empty()){ int t = q.front(); q.pop(); for(int u = 0;u <= 1;u++) for(pair <int , int> nxt : g[u][t]){ if(!nxt.second || dep[nxt.first]) continue; dep[nxt.first] = dep[t] + 1; q.push(nxt.first); } } return dep[T] > 0; }
int dfs(int x , int y){ //y 当前流量 if(x == T) return y; int sum = y; for(int t = 0;t <= 1;t++) for(int i = cur[t][x] , _ = g[t][x].size();i < _;i++){ cur[t][x] = i; int nxt = g[t][x][i].first , w = g[t][x][i].second; if(!w || dep[nxt] != dep[x] + 1) continue; int y = dfs(nxt , min(sum , w)); sum -= y; g[t][x][i].second -= y; g[t ^ 1][nxt][id[t][x][i]].second += y; if(!sum) return y; } return y - sum; }
inline void add(int x , int y , int w){ id[0][x].push_back(g[1][y].size()); id[1][y].push_back(g[0][x].size()); g[0][x].push_back({y , w}); g[1][y].push_back({x , 0}); }
inline int run(int s , int t){ S = s; T = t; int ret = 0; while(bfs()) ret += dfs(S , 1145141); return ret; }}
int n1 , n2 , m;
int main(void){ scanf("%d%d%d" , &n1 , &n2 , &m); while(m--){ int x , y; scanf("%d%d" , &x , &y); FSZ::add(x , y + n1 , 1); } for(int i = 1;i <= n1;i++) FSZ::add(0 , i , 1); for(int i = 1;i <= n2;i++) FSZ::add(i + n1 , n1 + n2 + 1 , 1); printf("%d\n" , FSZ::run(0 , n1 + n2 + 1));}Tarjan
haji 强连通分量
有向图,缩点。
int dfn[10005] , low[10005] , cnt;int st[10005] , bel[10005] , tot , chm;void dfs(int x){ st[++tot] = x; dfn[x] = low[x] = ++cnt; for(int nxt : g[x]){ if(!dfn[nxt]) dfs(nxt) , low[x] = min(low[x] , low[nxt]); else if(!bel[nxt]) // low[x] = min(low[x] , dfn[nxt]); } if(dfn[x] == low[x]){ chm++; do{ bel[st[tot]] = chm; b[chm] += a[st[tot--]]; }while(st[tot + 1] != x); }}...int dfn[10005] , low[10005] , cnt;int st[10005] , bel[10005] , tot , chm;void dfs(int x , int lt){ st[++tot] = x; dfn[x] = low[x] = ++cnt; for(pair <int , int> tmp : g[x]) if(lt != tmp.second){ int nxt = tmp.first; if(!dfn[nxt]) dfs(nxt , tmp.second ^ 1) , low[x] = min(low[x] , low[nxt]); else if(!bel[nxt]) //这里可以不判,加上也可以 low[x] = min(low[x] , dfn[nxt]); } if(dfn[x] == low[x]){ chm++; do{ bel[st[tot]] = chm; b[chm] += a[st[tot--]]; }while(st[tot + 1] != x); }}...for(int i = 1;i <= n;i++) if(!dfn[i]) dfs(i , 0);for(int i = 1;i <= n;i++) if(!dfn[i]) dfs(i);h 割点
无向图。
- 割点:删掉割点及和它相连的边后图不联通。
- 点双连通图:如果一个无向图去掉任意一个节点都连通,即不存在割点。
- 点双连通分量:一个无向图中的每个极大点双连通子图。
对于非根点,若存在一个的子节点满足,那么为割点。
对于根,若其有两颗及以上的子树,那么根为割点。
int dfn[10005] , low[10005] , cnt , R , ge[10005];void dfs(int x){ st[++tot] = x; dfn[x] = low[x] = ++cnt; int son = 0; for(pair <int , int> tmp : g[x]){ int nxt = tmp.first; if(!dfn[nxt]){ son++; dfs(nxt , tmp.second ^ 1); low[x] = min(low[x] , low[nxt]); if(x != r && low[nxt] >= dfn[x]) ge[x] = 1; } else if(tmp.second != lt)//注意这里可以特判不能走反边 low[x] = min(low[x] , dfn[nxt]); } if(x == R && son >= 2) ge[x] = 1;}...for(int i = 1;i <= n;i++) if(!dfn[i]) R = i , dfs(i , 0);注意和强连通分量的 low 的更新方法不同。
h 割边(桥)
无向图。
- 割边:删掉割边后图不联通。
- 边双连通图:如果一个无向图去掉任意一条边都连通,即不存在割边。
- 边双连通分量:一个无向图中的每个极大边双连通子图。
有和,边是割边当且仅当(较割点 不能取等)。
int dfn[10005] , low[10005] , cnt , R , ge[10005];void dfs(int x , int lt){ dfn[x] = low[x] = ++cnt; for(pair <int , int> tmp : g[x]){ int nxt = tmp.first; if(!dfn[nxt]){ dfs(nxt , tmp.second ^ 1); low[x] = min(low[x] , low[nxt]); if(low[nxt] > dfn[x]) //该边为割边。注意没有等号 } else if(lt != tmp.second)//注意不能走反边 一定要 low[x] = min(low[x] , dfn[nxt]); }}...for(int i = 1;i <= n;i++) if(!dfn[i]) dfs(i , 0);haji 边双联通分量
无向图。
int dfn[10005] , low[10005] , cnt;int st[10005] , bel[10005] , tot , chm;void dfs(int x , int lt){ st[++tot] = x; dfn[x] = low[x] = ++cnt; for(pair <int , int> tmp : g[x]) if(lt != tmp.second){ int nxt = tmp.first; if(!dfn[nxt]) dfs(nxt , tmp.second ^ 1) , low[x] = min(low[x] , low[nxt]); else if(!bel[nxt]) //这里可以不判,加上也可以 low[x] = min(low[x] , dfn[nxt]); } if(dfn[x] == low[x]){ chm++; do{ bel[st[tot]] = chm; b[chm] += a[st[tot--]]; }while(st[tot + 1] != x); }}...for(int i = 1;i <= n;i++) if(!dfn[i]) dfs(i , 0);总结
强连通分量和边双很类似,唯一区别是边双不能走反边(第 6 行)
无向图的都可以判反边。其中边双是直接不能进循环,割点割边是走过的时候判。
割点,割边。
注意强连通分量和边双的加连通块时是:do{...}while(st[tot + 1] != x);
共同点是若没走过,low 更新是low[x] = min(low[x] , low[nxt]);
其他情况( if 不同)是low[x] = min(low[x] , dfn[nxt])。
特殊点:割点特判根节点;注意森林。
我们发现点双没啥用,就不写了(割点也没用)。
树
kkk 重构树
每次合并连通块,我们新建一个点做这两连通块的父亲,其点权为连接的边的边权,这样能建成二叉树(二叉堆)。
- 除根节点外,每个节点对应最小生成树的一条边。
- 点权随编号单调。
- 最小生成树中到路径上最大边权为的点权。
hajim lca(dfn 序)
预处理
查询
lca(x,y) 为中深度最小的点的父亲。 实现时用 dfn 序判断即可。
原理:lca=id[min{dfn[fa[i]]}](dfn[u]+1<=i<=dfn[v])
int n , m , s;vector <int> g[500005];
int lg[500005];int dfn[500005] , cnt , st[500005][22];void dfs(int x , int fa){ st[dfn[x] = ++cnt][0] = fa; for(int nxt : g[x]) if(nxt != fa) dfs(nxt , x);}
inline int ST_MIN(int x , int y){ return (dfn[x] < dfn[y]? (x) : (y)); }inline void init(){ dfs(s , 0); for(int i = 2;i <= n;i++) lg[i] = lg[i >> 1] + 1; for(int k = 1;k <= lg[n];k++) for(int i = 1;i + (1 << k) - 1 <= n;i++) st[i][k] = ST_MIN(st[i][k - 1] , st[i + (1 << (k - 1))][k - 1]);}
inline int lca(int x , int y){ if(x == y) return x; if((x = dfn[x]) > (y = dfn[y])) swap(x , y); int le = lg[y - x++]; return ST_MIN(st[x][le] , st[y - (1 << le) + 1][le]);}haj 重心
haj 直径
dfs 两次,第一次走到最远的节点,以为根再跑一次,到,为直径。
haj 树剖
int son[100005] , fa[100005] , dep[100005] , siz[100005];void dfs1(int x , int ff , int dd){ siz[x] = 1 , fa[x] = ff , dep[x] = dd; for(int nxt : g[x]) if(nxt != ff){ dfs1(nxt , x , dd + 1); siz[x] += siz[nxt]; if(siz[nxt] > siz[son[x]]) son[x] = nxt; }}
int top[100005] , id[100005] , w[100005] , tr_cnt;void dfs2(int x , int tp){ top[x] = tp; w[id[x] = ++tr_cnt] = a[x]; if(son[x]) dfs2(son[x] , tp); for(int nxt : g[x]) if(nxt != fa[x] && nxt != son[x]) dfs2(nxt , nxt);}
inline void upd1(int x , int y , int k){ while(top[x] != top[y]){ if(dep[top[x]] < dep[top[y]]) upd(1 , 1 , n , id[top[y]] , id[y] , k) , y = fa[top[y]]; else upd(1 , 1 , n , id[top[x]] , id[x] , k) , x = fa[top[x]]; } if(dep[x] > dep[y]) upd(1 , 1 , n , id[y] , id[x] , k); else upd(1 , 1 , n , id[x] , id[y] , k);}数论
ha 线性筛
phi,mu,minp。
可以筛积性函数。
在数论中,若函数 满足 ,且 对任意互质的 都成立,则 为 积性函数。
#include <cstdio>#include <algorithm>using namespace std;
bool vis[N]; int p[N] , cnt;int mu[N] , phi[N] , minp[N];void init(){ mu[1] = phi[1] = 1; for(int i = 2;i <= N;i++){ if(!vis[i]) p[++cnt] = i , mu[i] = -1 , phi[i] = minp[i] = i - 1; for(int j = 1;j <= cnt && i * p[j] <= N;j++){ vis[i * p[j]] = 1; if(i % p[j] == 0){ mu[i * p[j]] = 0; phi[i * p[j]] = phi[i] * p[j]; break; } phi[i * p[j]] = phi[i] * phi[p[j] - 1]; mu[i * p[j]] = -mu[i]; } }}ha 数论分块
for(int l = 1 , r;l <= n;l = r + 1){ r = n / (n / l); ret += f(n / l);}linux
-Wall,-Wextra,开启更多警告。-fsanitize=address,leak,undefined,查数组越界/未定义行为。注意仍有小部分错误可能无法查出,如 string 访问越界,不可过分依赖此选项。同时,开启此选项后程序运行效率无意义,所以应关闭此选项后再测试运行时间。cd BJ-001\abc,进入文件夹;cd ..回到上级目录。ulimit -s 1048576,开栈空间(单位是 KB)。ulimit -v 1048576,开内存空间,务必用题目规定的空间限制测试。time ./abc,查看程序运行时间。size ./abc,查看程序内存占用(单位是 B)。- 按上箭头,复制上一条命令。
Ctrl + C,强制终止程序。diff abc.out abc.ans -Bb,对比输出文件和答案文件是否相同,-Bb忽略行末空格和文末回车。
部分信息可能已经过时